March, 2017
Audio event detection aims at discovering the sound elements inside an audio clip. In this topic, we try to discover not only the sound events happened in an audio clip (clip-level information) but also the temporal positions of the detected sounds (frame-level information). Since creating frame-level annotated data can be extremely time-consuming, we proposed a model based on convolutional neural networks that relies on data with only clip-level labels (weakly supervised data) for training. However, the model is still able to find out the frame-level information inside every audio clip.
Usage of Audio Event Detection
Audio event detection (AED), or sound event detection (SED), can be used in many scenarios. For example, when multimedia files are uploaded to a website, we can automatically recognize its contents by analyzing the audio. If AED is applied to surveillance cameras and home security devices, they can alert us when abnormal sound events such as screaming, shouting, or gun-shots occur. Special purposes of SED also include classification of breath and snore, urban sounds, and animal species.
More information about AED:
- Sound Event Detection written by Toni Heittola
- DCASE2016
- IEEE/ACM TASLP Special Issue on Sound Scene and Event Analysis
Weakly Supervised Learning (WSL)
In our case, weakly supervised learning means to use some noisier data to train our model. These data may contain several sounds that appear simultaneously, may have louder background noise, may be long and redundant (the target sounds show up in only a small portion of each clip), etc. Thus, in addition to searching for the appearance of the sound events, we have to find their locations as well.
Why WSL?
Conventionally, we train models with data containing only and clearly the labeled sound, which we consider as fully supervised data. However, such richly annotated data are generally hard to come by, and producing them can be very time-consuming. Additionally, in many cases, multiple audio events may occur at the same time, making it harder to collect pure and clean training data. The difficulty grows even higher when we try to scale up the number of sound classes.
On online platforms like Freesound, there are a lot of audio clips tagged with specific events. However, instead of being omnipresent, the events may appear for a short period of time in a clip. Moreover, we do not even know the location of those events. If we can train a competitive model with these weakly supervised clips, our training data can be easily expanded.
Difficulties of WSL
The primary difficulty of WSL is to locate the training targets. To solve this problem, we create a fully convolutional neural networks (FCN) and apply a global pooling layer at the end of the model. With a global pooling layer, the model can select the most potential segment to be a final clip-level prediction. It is still possible that the model picks wrong targets, but we believe it can reduce erroneous selection with more training data.
Another problem is that the target sounds may vary in amplitude significantly between training clips. Thus, we do data augmentation by adding and reducing 5db to the volume of every clip. As a result, we get triple training data and should make the model less sensitive to the effect of diverse volume.
Related work of WSL:
- Audio Event Detection using Weakly Labeled Data
- Event Localization in Music Auto-tagging
- Weakly Supervised Object Recognition with Convolutional Neural Networks
For more detail about our current model, please check out our paper!
The following content demonstrates the result of our paper:
T.-W. Su, J.-Y. Liu, Y.-H. Yang, Weakly-Supervised Audio Event Detection using Event-Specific Gaussian Filters and Fully Convolutional Networks, in proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, USA. March, 2017. [PDF]
Abstract
Audio event detection aims at discovering the elements inside an audio clip. In addition to labeling the clips with the audio events, we want to find out the temporal locations of these events. However, creating clearly annotated training data can be time-consuming. Therefore, we provide a model based on convolutional neural networks that relies only on weakly-supervised data for training. These data can be directly obtained from online platforms, such as Freesound, with the clip-level labels assigned by the uploaders. The structure of our model is extended to a fully convolutional networks, and an event-specific Gaussian filter layer is designed to advance its learning ability. Besides, this model is able to detect frame-level information, e.g., the temporal position of sounds, even when it is trained merely with clip-level labels.
Datasets
Our model is trained with UrbanSound Dataset (US). We tested our clip-level result on UrbanSound8K Dataset (8K) and frame-level result on US. We used ten-folded cross-validation for testing. There are totally 1302 files in US and 8732 files in 8K.
| Class | # of Data (US) | # of Data (8K) |
|---|---|---|
| Air conditioner | 64 | 1000 |
| Car horn | 125 | 429 |
| Children playing | 158 | 1000 |
| Dog bark | 337 | 1000 |
| Drilling | 119 | 1000 |
| Engine idling | 97 | 1000 |
| Gun shot | 117 | 347 |
| Jackhammer | 45 | 1000 |
| Siren | 74 | 929 |
| Street music | 166 | 1000 |
| Total | 1302 | 8732 |
Evaluation Settings
Input features
Log-melspectrogram:
- Sampling rate: 44100Hz
- Window size of STFT: [1024, 4096, 16384] for multi-scale
- Hop size of STFT: 512
- Number of Mel bands: 128
Delta:
- Width to compute: 9
- The order of the difference operator: 1
Clip-level Result
We achieved an overall accuracy of 59.88%, and the accuracy of each class is shown below.
| Class | Accuracy (%) | Class | Accuracy (%) |
|---|---|---|---|
| Air conditioner | 76.7 | Engine idling | 51.8 |
| Car horn | 69.0 | Gun shot | 94.4 |
| Children playing | 41.8 | Jackhammer | 39.8 |
| Dog bark | 79.5 | Siren | 59.0 |
| Drilling | 52.3 | Street music | 61.3 |
To be more precise, we provide the confusion matrices.
| Abbr | Class | Abbr | Class |
|---|---|---|---|
| AC | Air conditioner | EI | Engine idling |
| CH | Car horn | GS | Gun shot |
| CP | Children playing | JA | Jackhammer |
| DB | Dog bark | SI | Siren |
| DR | Drilling | SM | Street music |
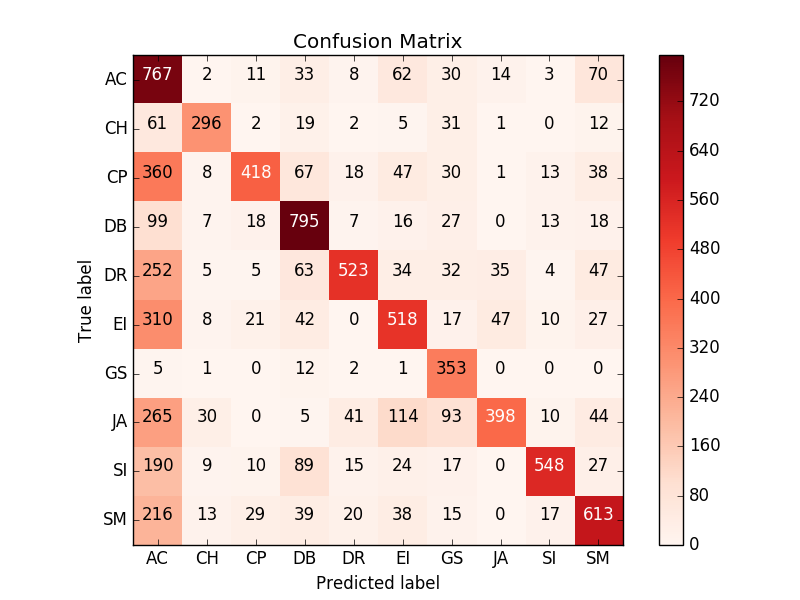
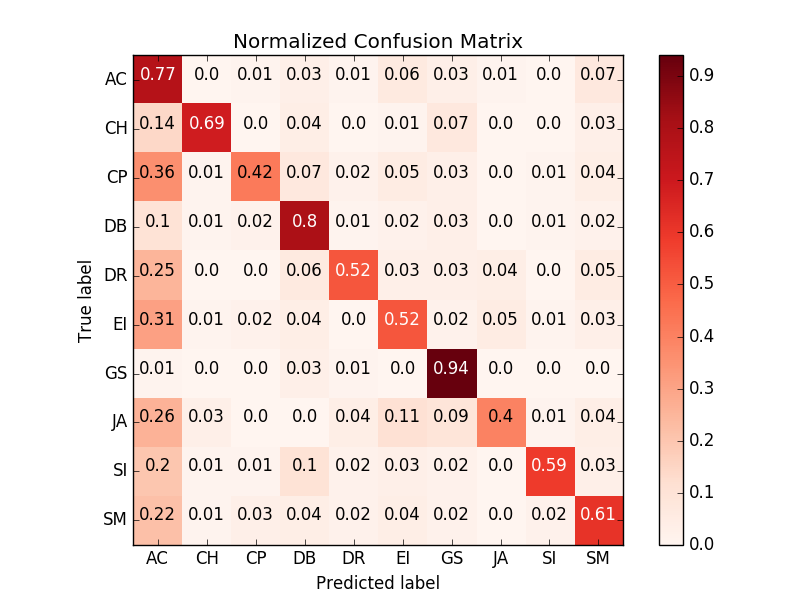
From these matrices, we can see that the model correctly classified most of the clips. The largest problem appears in the first column, that is, most of the incorrect results are predicted to be “air conditioner” (AC). As we analyze the result, we found that most of the clips classified to AC have a final prediction smaller than 0.01 (the scale is from 0 to 1). This phenomenon only severely happened in AC, so we speculate that the AC class has learned something that not only appears in many clips but also generally small in magnitude – the noise.
Frame-level Result
The overall area-under-ROC-curve (AUC) score is 0.738, and the AUC score of each class is shown below.
| Class | AUC score | Class | AUC score |
|---|---|---|---|
| Air conditioner | 0.612 | Engine idling | 0.688 |
| Car horn | 0.807 | Gun shot | 0.921 |
| Children playing | 0.594 | Jackhammer | 0.704 |
| Dog bark | 0.790 | Siren | 0.763 |
| Drilling | 0.764 | Street music | 0.737 |
In the following part, we will discuss the frame-level result by looking into their final predictions.
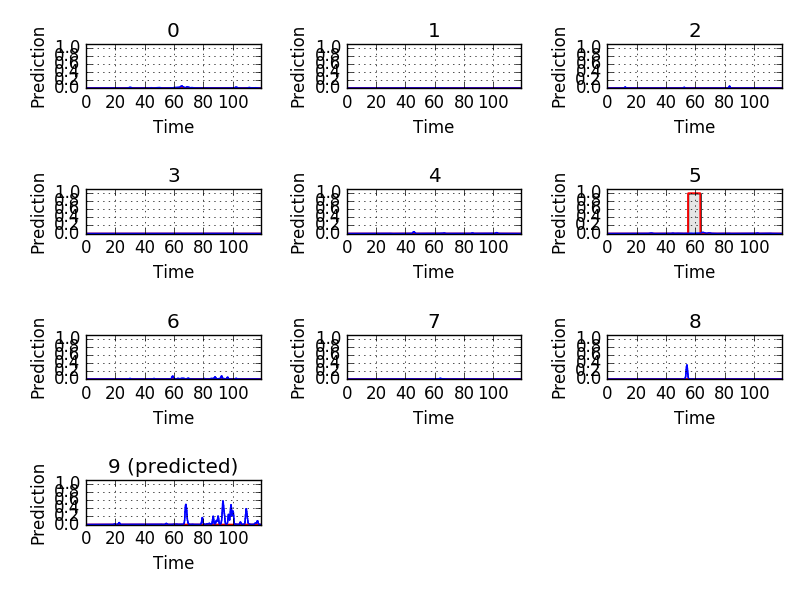
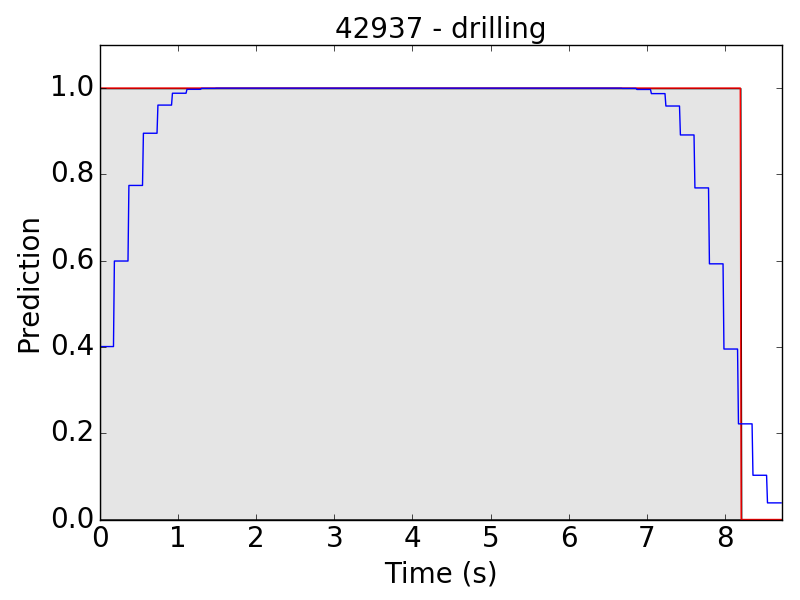
First, let’s see some plots of the successful results. Blue line represents the final prediction, and red line denotes the ground truth.
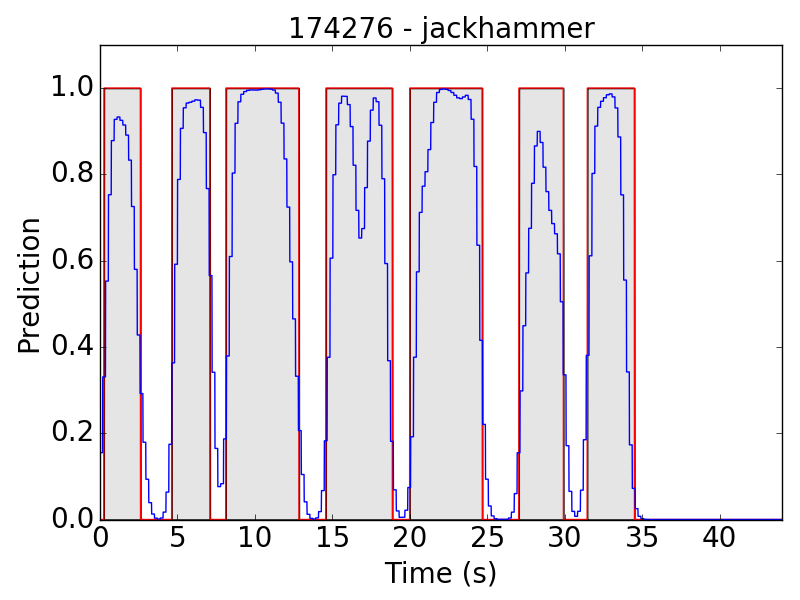
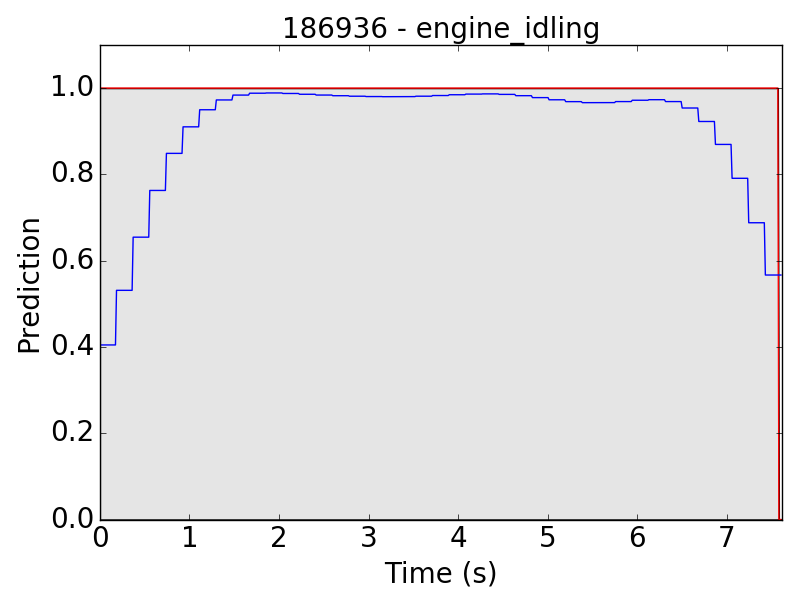
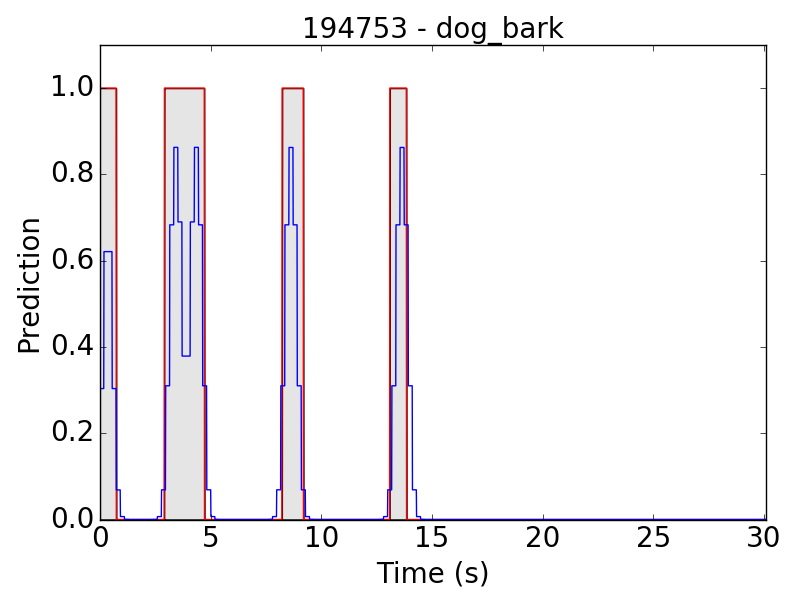
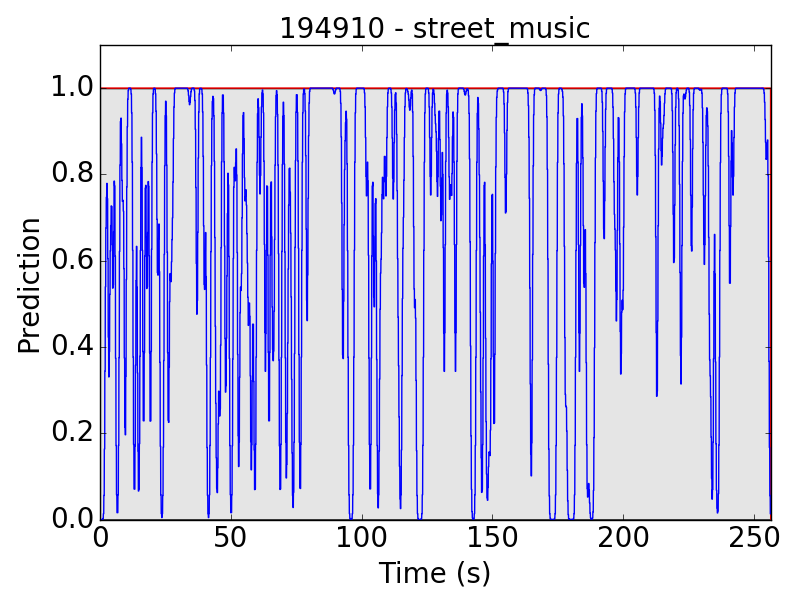
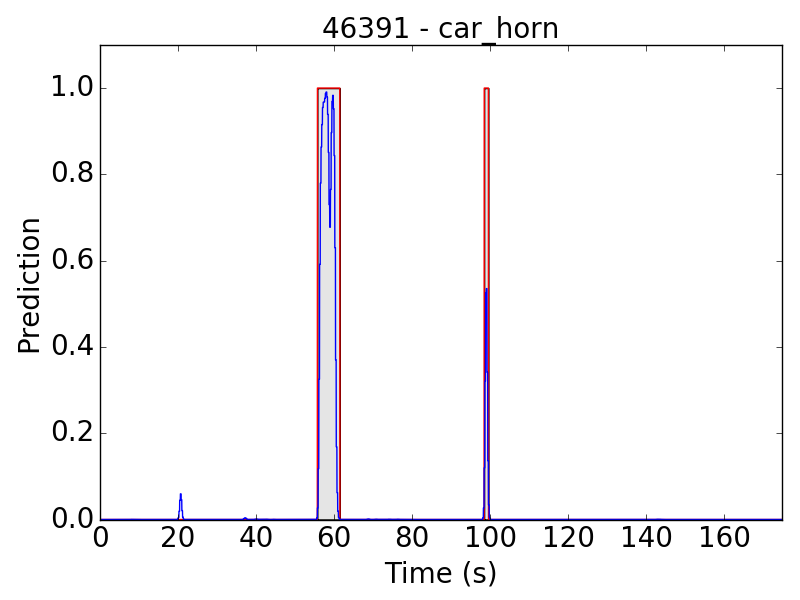
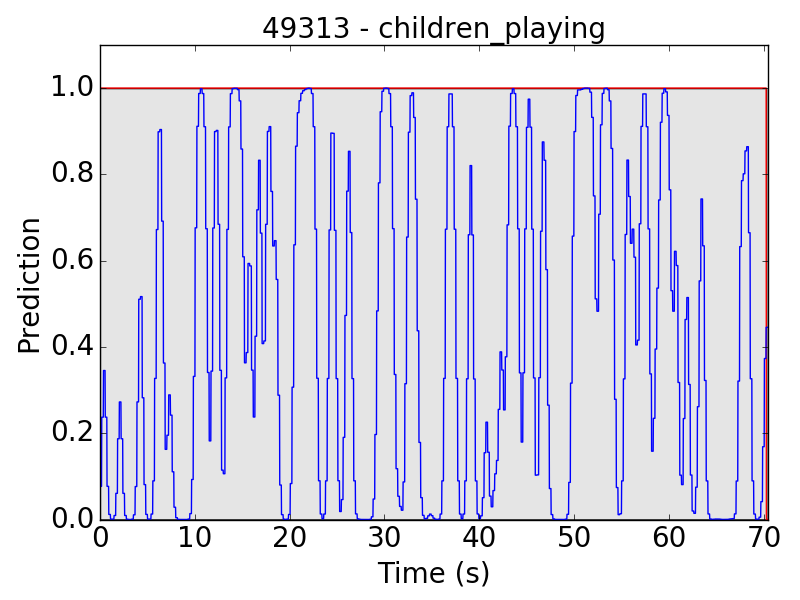
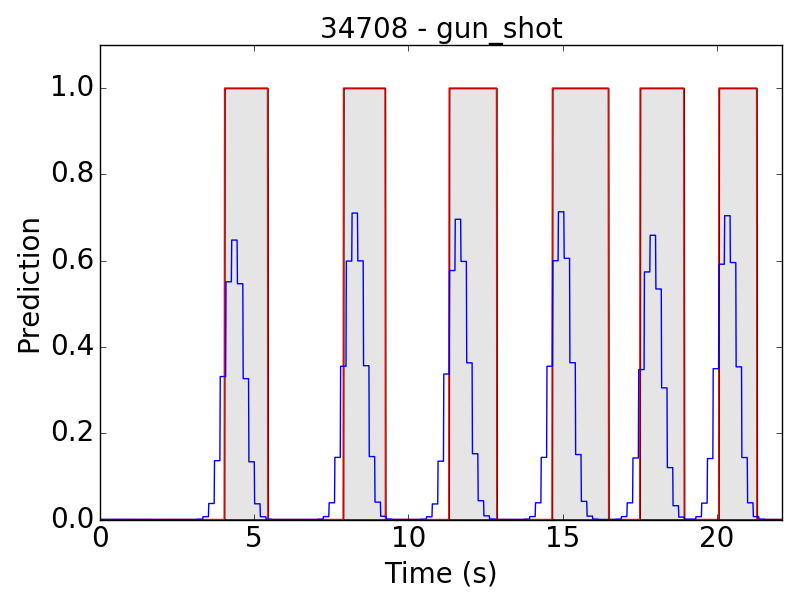
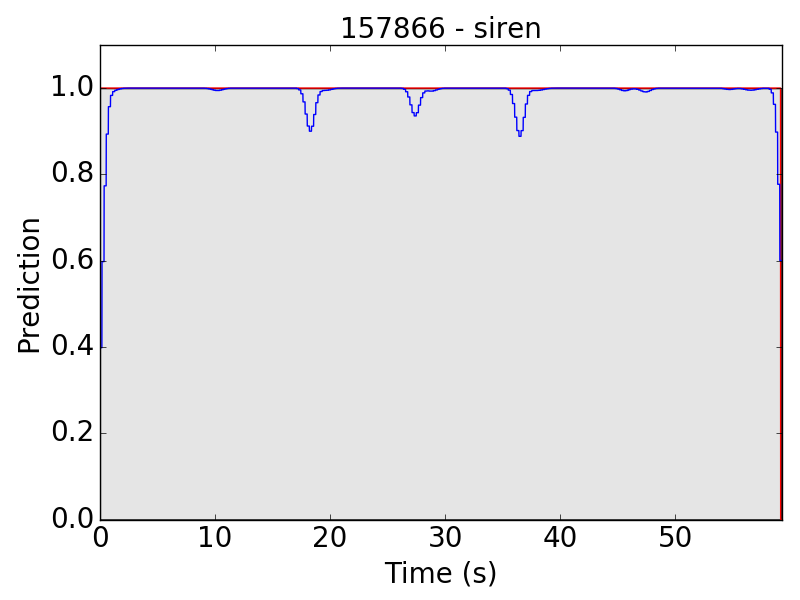
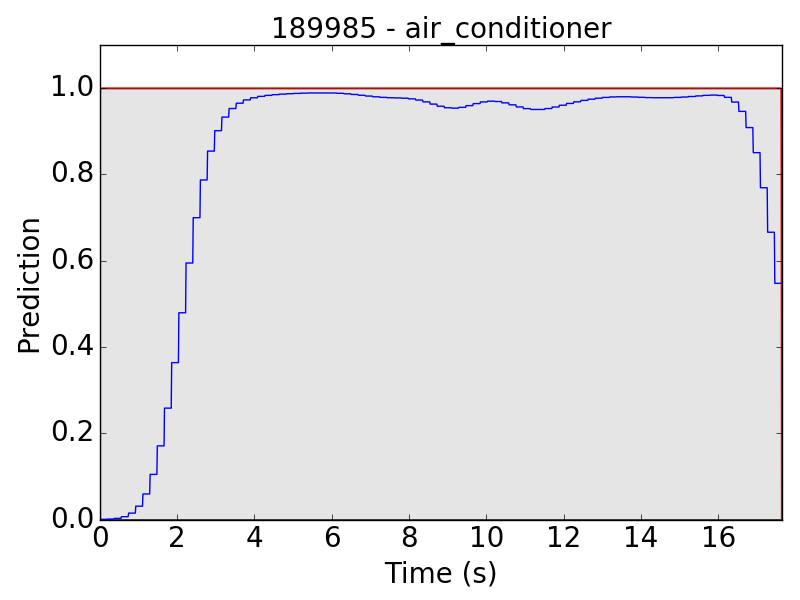
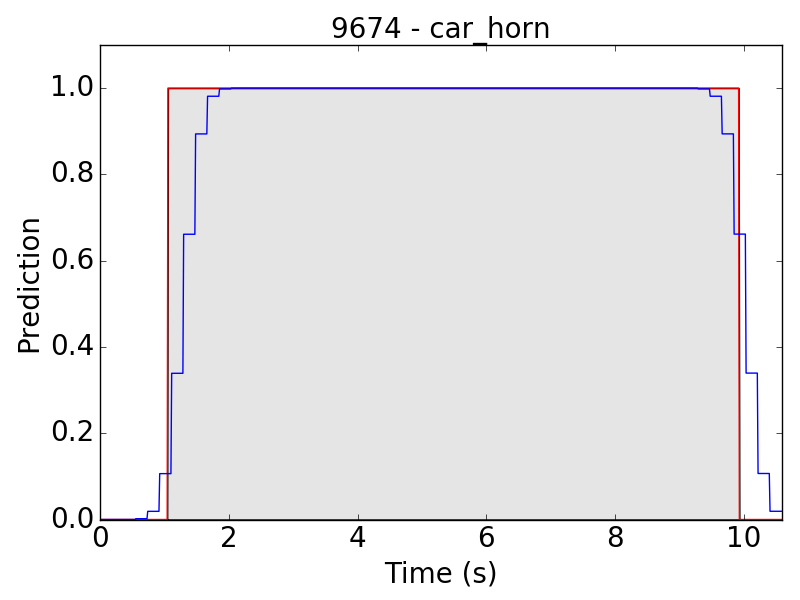
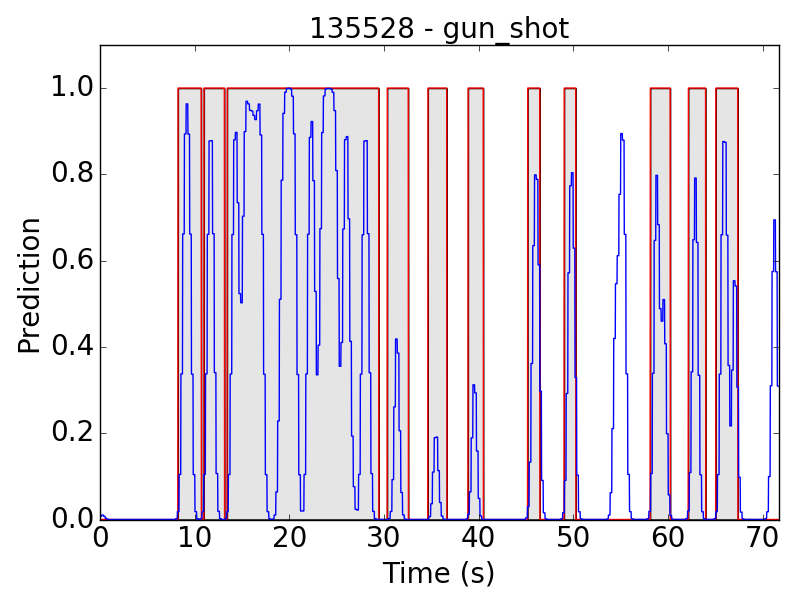
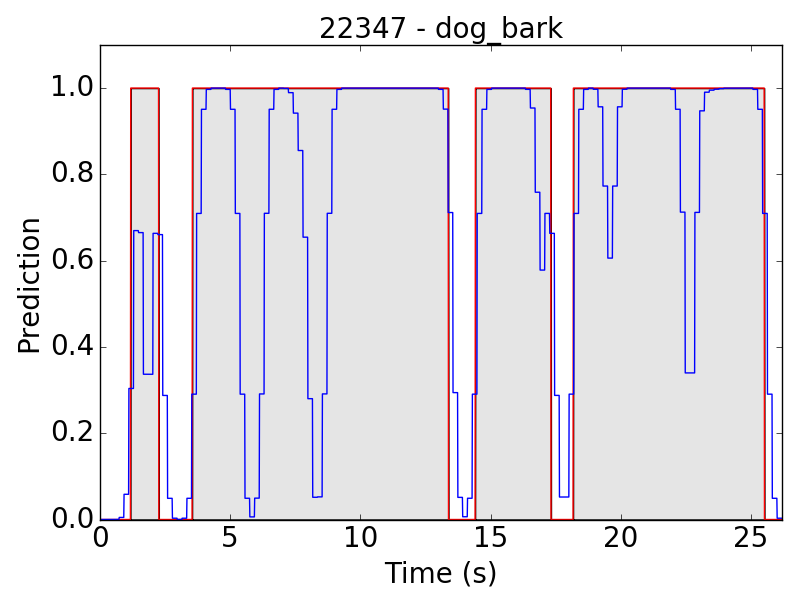
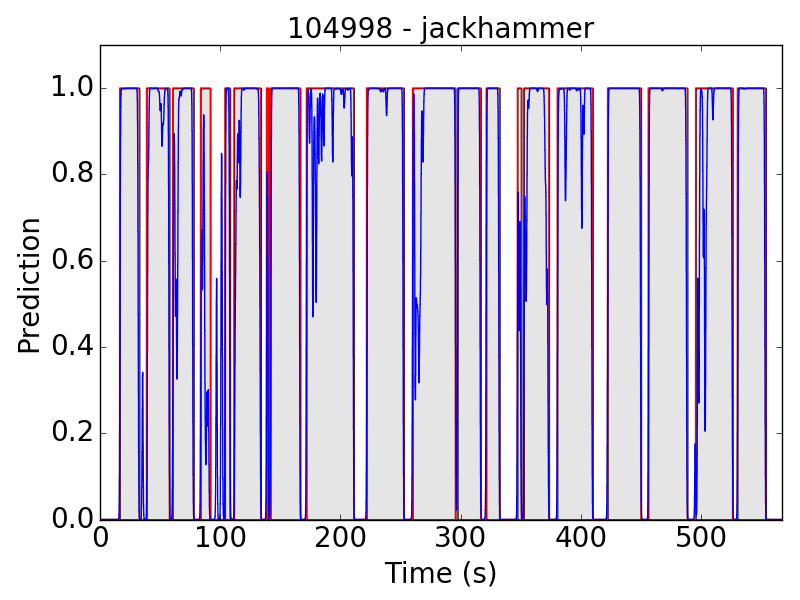
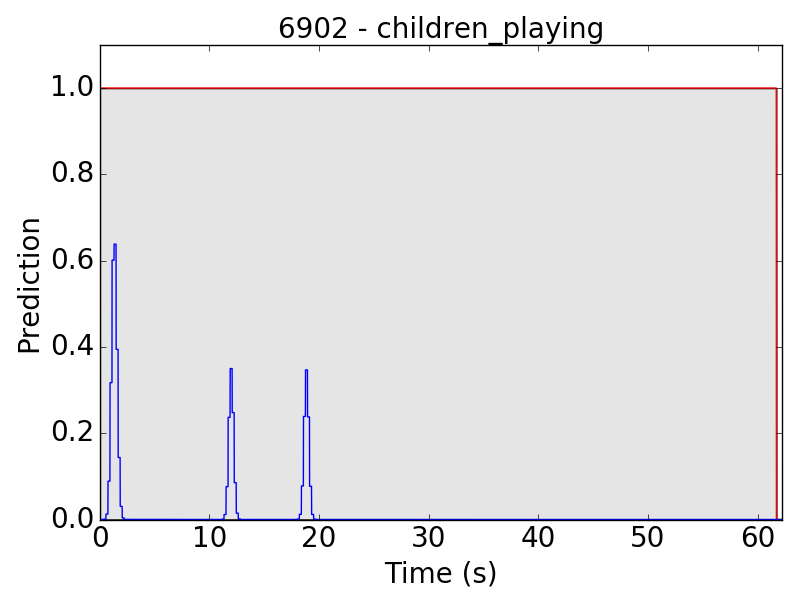
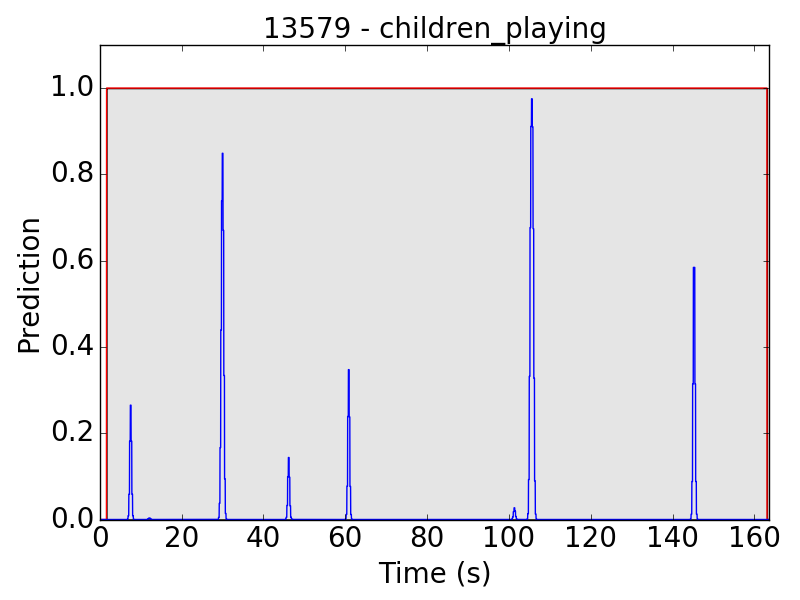
However, there are still some flaws in the results. Take “children playing” (CP) for example, we expect the event to be a long continuous event, but our model detected only the particularly loud parts, such as yelling and shouting, of children’s sound. Therefore, the frame-level results appear to be like this:
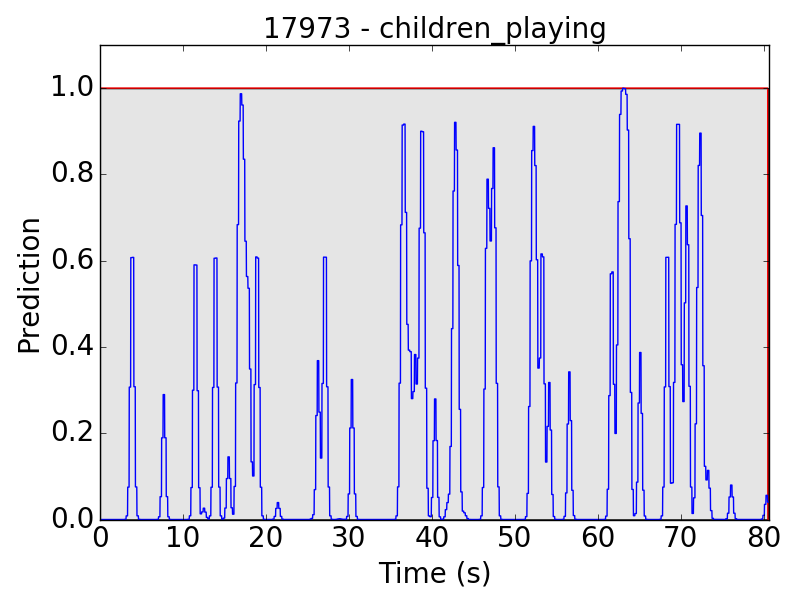
The same problem happens in “street music” (SM) as well:
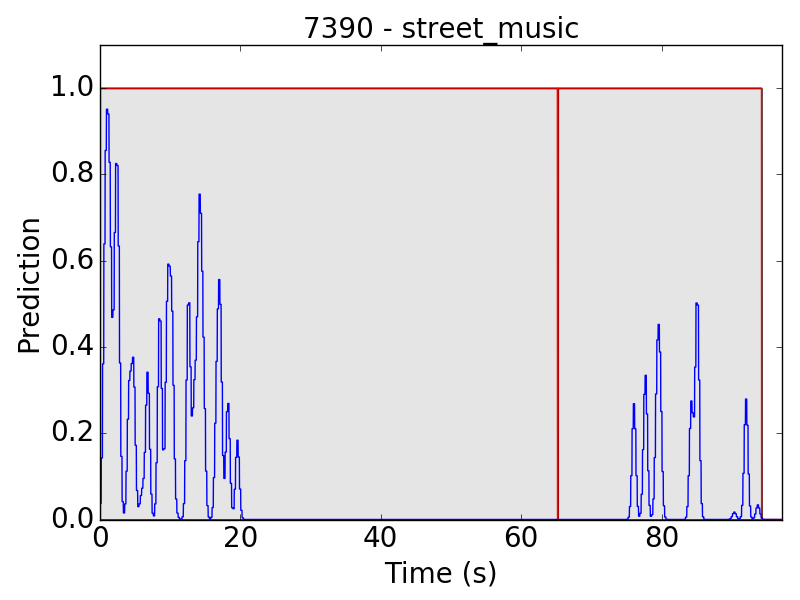
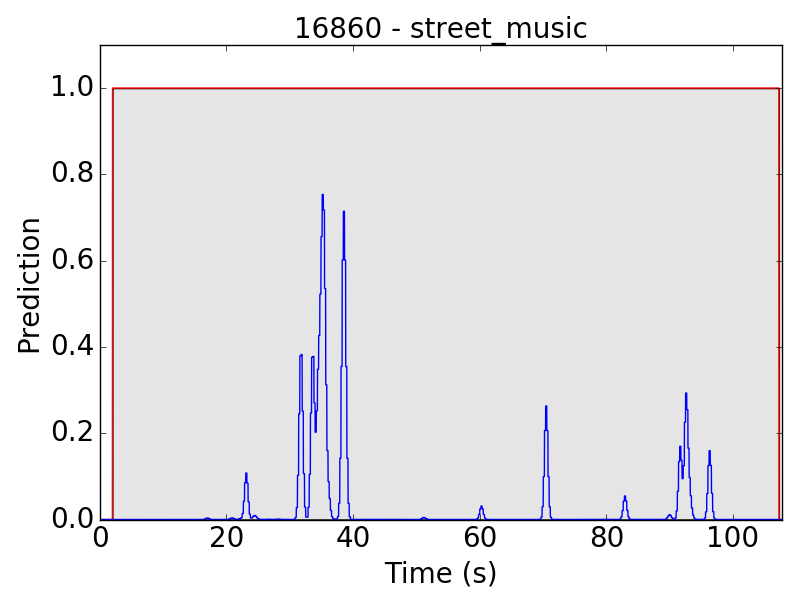
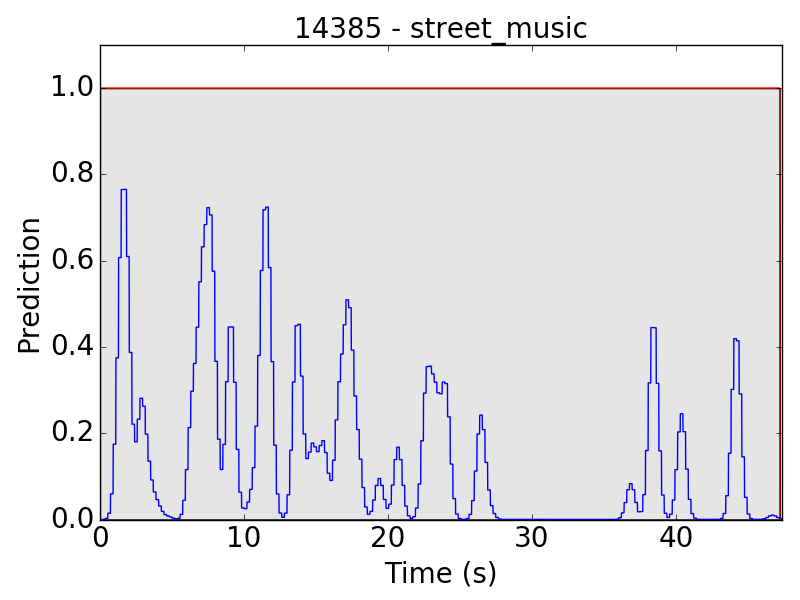
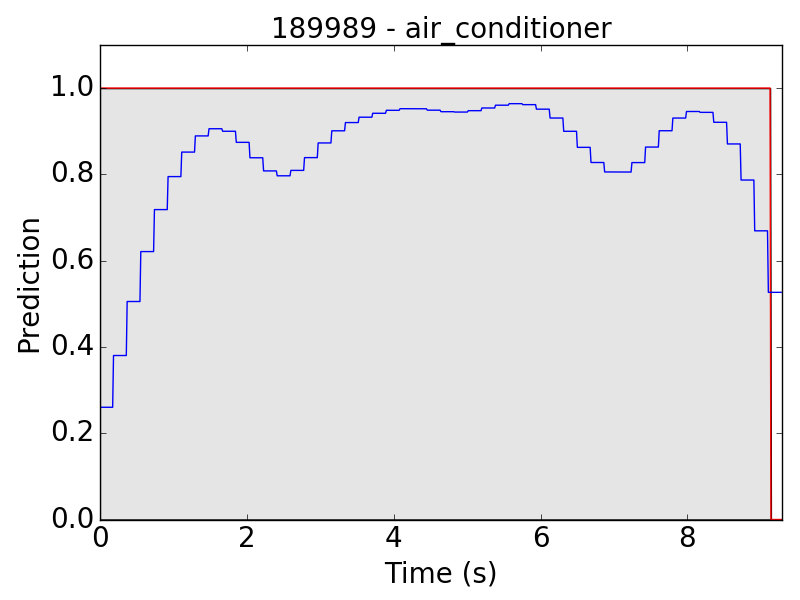
Another problem occurs in “air conditioner” (AC). As mentioned in the clip-level evaluation, many clips of AC result in small predicted values (lower than 0.01 in the scale of 0~1). This problem leads to the following plots:
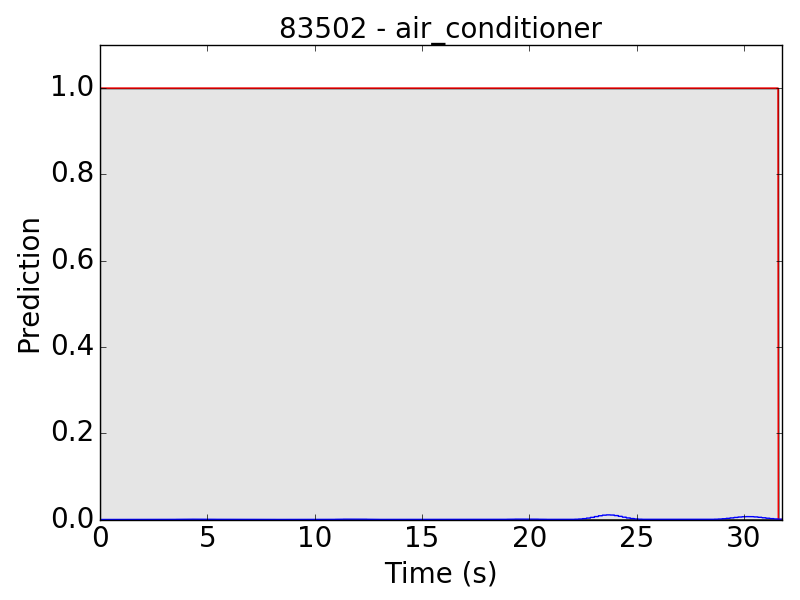
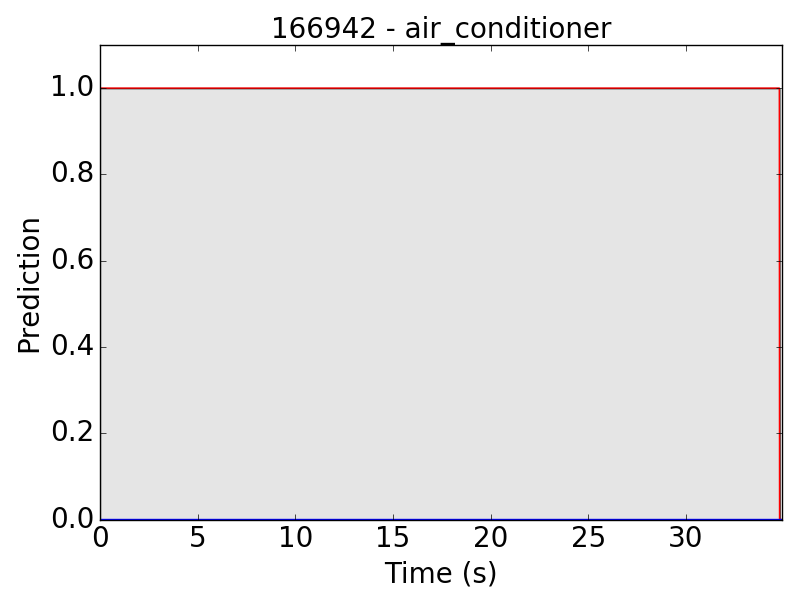
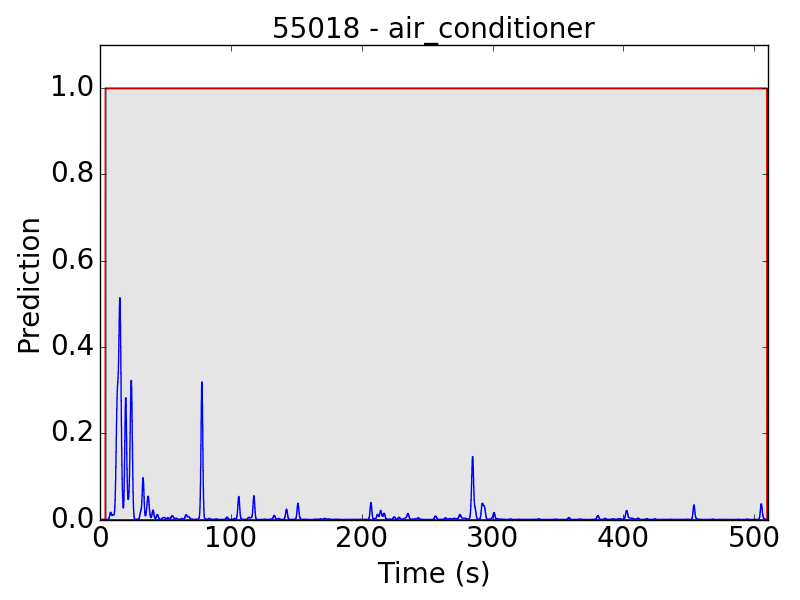
Similarly, the problem sometimes also occurs in other classes:
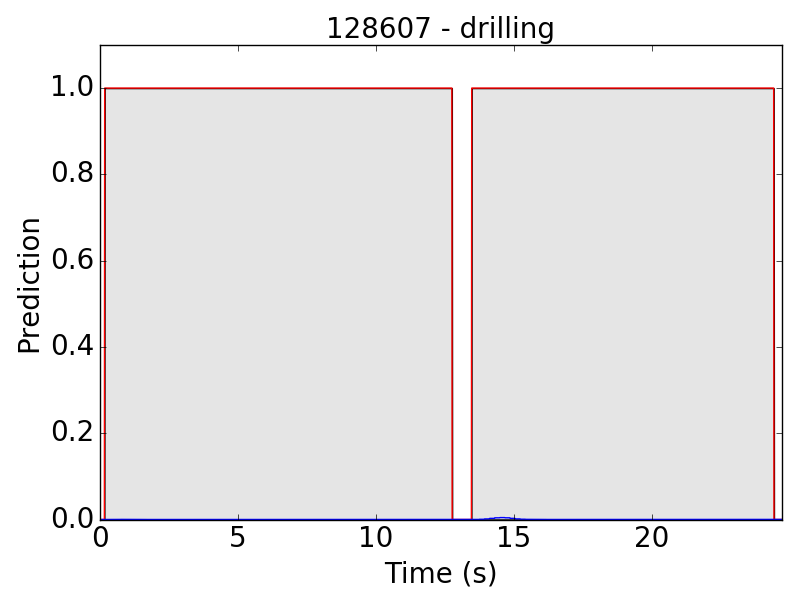
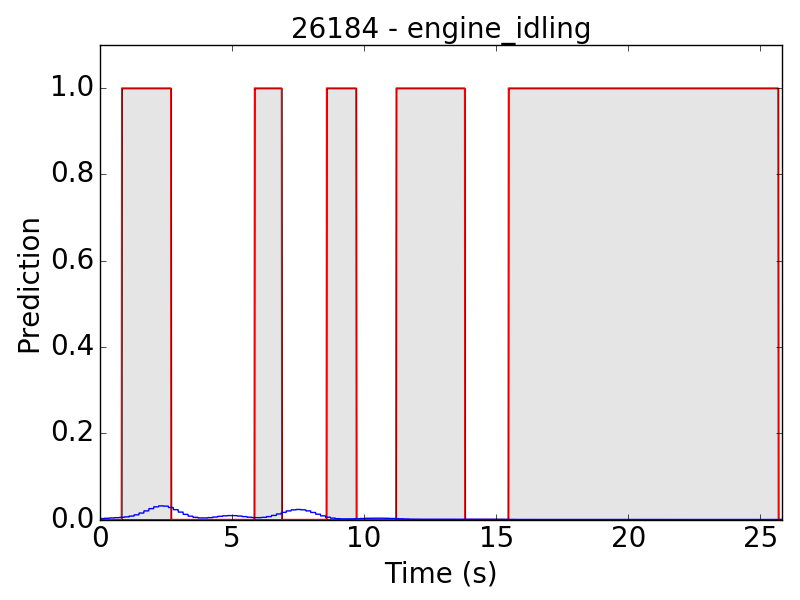
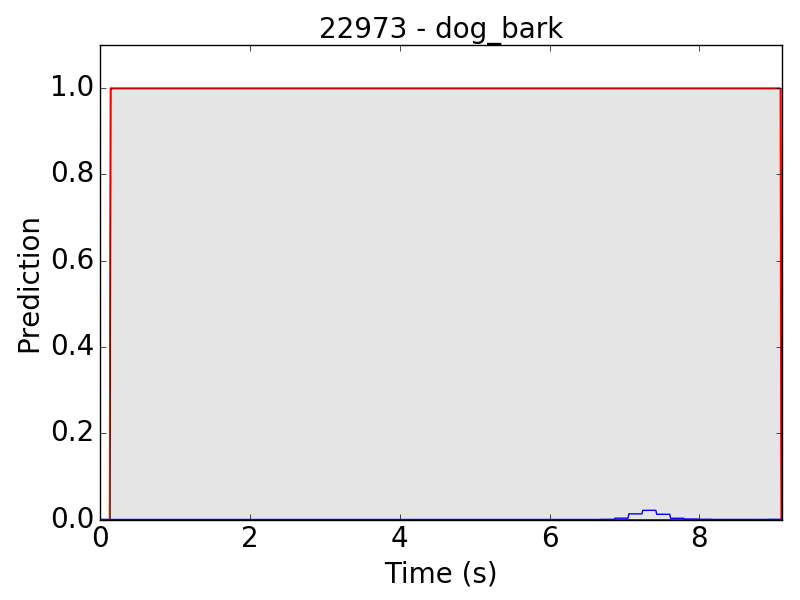
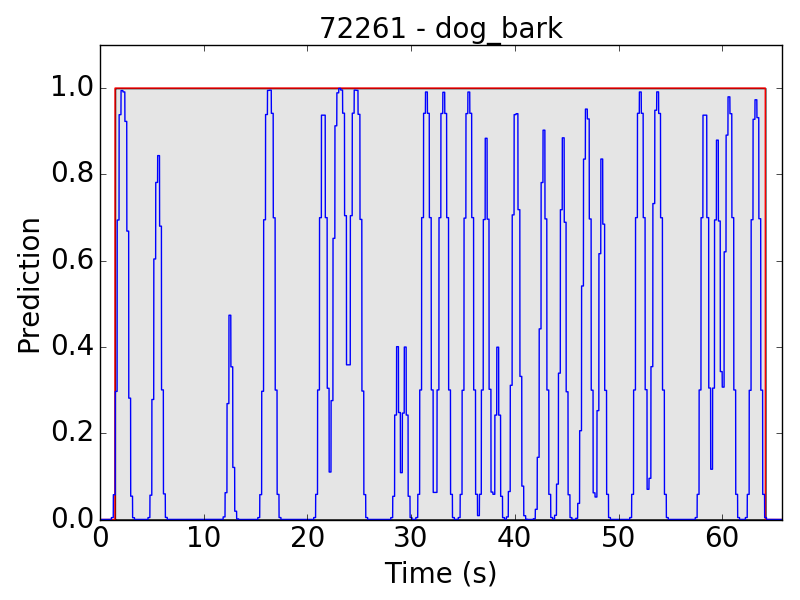
Even though we have done data augmentation on volume, the model is still relatively weak at detecting background sound. In the following file, we can hear two dogs barking, one in the foreground and the other in the background. The model detected only the sounds from foreground dog.
In some examples, we found wrong annotations. As in 77927.wav, we detected a significant amount of street music, but the ground truth only labeled several small dog barks.
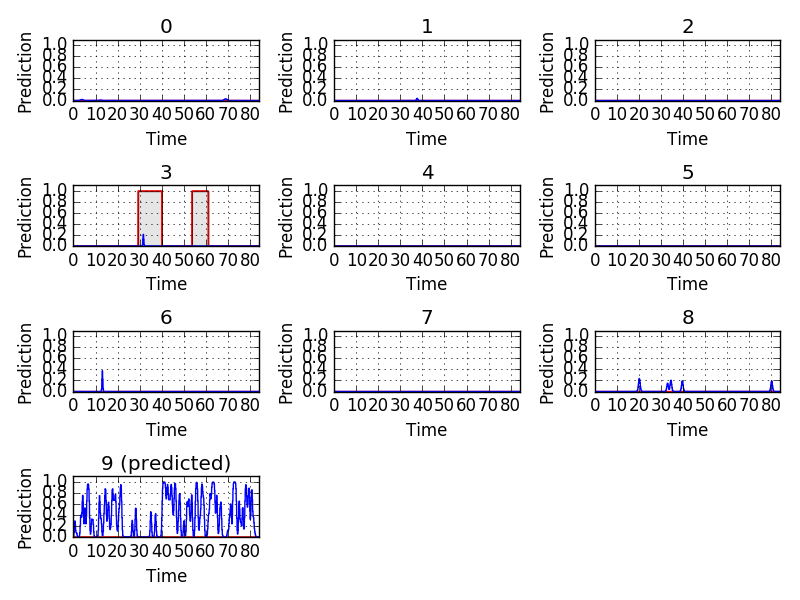
The same error appears in 106905.aif. While the ground truth is engine idling, we can still hear the siren and street music.